达梦数据库迁移教程
本文最后更新于 2023-10-13,文章内容可能已经过时。
数据库迁移教程
本教程用于从postgres数据库迁移到达梦数据库.
1.准备工作:
1.1 postgres:
正确安装postgres(如果连接远程数据库则不需要在本地安装,有数据库可视化工具即可).
参看postgresql保姆级安装教程pgsql安装食猫竹的博客-CSDN博客
注意:
如果pgsql版本过高,可能会出现navicat和pgsql版本不匹配问题,建议下载pgsql11.21版本.
首次安装完成postgres后,需要登陆pg admin4应用程序(在搜索框直接搜索即可)
登陆后在左上角注册一下server
输入一下刚才指定的密码,然后就可以使用navicat等数据库连接工具访问了。
1.2 达梦数据库:
达梦数据库安装与初始化超详细教程_陈老老老板的博客-CSDN博客
正确安装达梦数据库(远程连接也需要安装).
安装达梦数据库后会出现一堆DM管理工具,能正确启动即可.
2.迁移过程:
2.1 达梦数据库设置
使用DM管理工具来管理达梦数据库.
在此处连接远程数据库.
连接成功后截图如下:
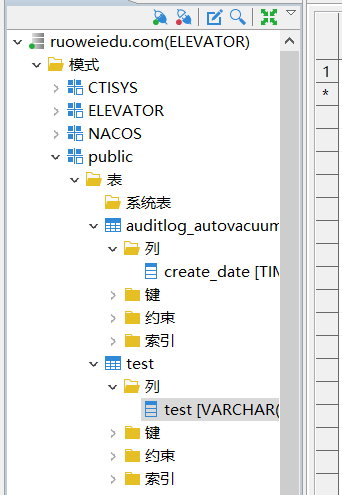
进行数据库迁移之前,要确保数据库中的数据库存在,表存不存在都可以进行迁移.
2.2 导入数据进入pgsql:
进行迁移之前,要先从sql文件中把数据导入进pgsql,由于该sql文件本身过大而且不能运行,所以要进行一些操作.
2.2.1 获取表结构:
新建数据库,运行仅含有表结构的sql文件,生成表结构.
如果该文件无法运行,用记事本打开,删除文件开头的模式即可正常运行.
2.2.2 拆分文件:
拆分过大的sql文件,方便接下来处理.
按大小拆分:用git bash打开
split 文件名 -b 每个文件的大小按照特征行拆分:python代码
注意修改文件路径.
def split_file(input_file, output_prefix, feature):
with open(input_file, 'r', encoding='utf-8') as f:
lines = f.readlines()
current_output_file = None
file_count = 1
for line in lines:
if feature in line:
if current_output_file:
current_output_file.close()
file_count += 1
output_file_name = f"{output_prefix}_{file_count}.txt"
current_output_file = open(output_file_name, 'w')
if current_output_file:
current_output_file.write(line)
if current_output_file:
current_output_file.close()
if __name__ == "__main__":
input_file = "C:\\Users\\wpy\\Desktop\\xaa.txt" # 输入文件路径
output_prefix = "C:\\Users\\wpy\\Desktop\\output" # 输出文件名前缀
feature = "-- Data for Name:" # 特征行的特征
split_file(input_file, output_prefix, feature)
print("File split completed.")
建议先根据大小进行拆分,然后在对拆分过一次的文件进行按特征行拆分的操作,避免电脑卡死.
2.2.2 修改格式:
在数据库里找到要迁移的表(此时只有表结构而无数据),在里面添加一行数据,然后选择导出sql脚本.选择结构和数据,这样就得到了一个sql文件,结构类似如下:
/*
Navicat Premium Data Transfer
Source Server : weihai
Source Server Type : PostgreSQL
Source Server Version : 110021
Source Host : localhost:7777
Source Catalog : postgres
Source Schema : public
Target Server Type : PostgreSQL
Target Server Version : 110021
File Encoding : 65001
Date: 31/08/2023 22:20:03
*/
-- ----------------------------
-- Table structure for auditlog_log_line
-- ----------------------------
DROP TABLE IF EXISTS "public"."auditlog_log_line";
CREATE TABLE "public"."auditlog_log_line" (
"id" int4 NOT NULL DEFAULT nextval('auditlog_log_line_id_seq'::regclass),
"create_uid" int4,
"log_id" int4,
"new_value_text" text COLLATE "pg_catalog"."default",
"field_id" int4 NOT NULL,
"write_uid" int4,
"create_date" timestamp(6),
"old_value_text" text COLLATE "pg_catalog"."default",
"write_date" timestamp(6),
"new_value" text COLLATE "pg_catalog"."default",
"old_value" text COLLATE "pg_catalog"."default"
)
;
COMMENT ON COLUMN "public"."auditlog_log_line"."create_uid" IS 'Created by';
COMMENT ON COLUMN "public"."auditlog_log_line"."log_id" IS 'Log';
COMMENT ON COLUMN "public"."auditlog_log_line"."new_value_text" IS '更新后数据';
COMMENT ON COLUMN "public"."auditlog_log_line"."field_id" IS '字段名';
COMMENT ON COLUMN "public"."auditlog_log_line"."write_uid" IS 'Last Updated by';
COMMENT ON COLUMN "public"."auditlog_log_line"."create_date" IS 'Created on';
COMMENT ON COLUMN "public"."auditlog_log_line"."old_value_text" IS '旧数据';
COMMENT ON COLUMN "public"."auditlog_log_line"."write_date" IS 'Last Updated on';
COMMENT ON COLUMN "public"."auditlog_log_line"."new_value" IS '更新后数据';
COMMENT ON COLUMN "public"."auditlog_log_line"."old_value" IS '更新前数据';
COMMENT ON TABLE "public"."auditlog_log_line" IS 'Auditlog - Log details (fields updated)';
-- ----------------------------
-- Records of auditlog_log_line
-- ----------------------------
INSERT INTO "public"."auditlog_log_line" VALUES (1, 1, 1, '电梯安全生产责任保险', 1716, 1, '2021-12-30 06:10:01.749365', NULL, '2021-12-30 06:10:01.749365', '电梯安全生产责任保险', NULL);
INSERT INTO "public"."auditlog_log_line" VALUES (2, 1, 1, '浦林成山(山东)轮胎有限公司', 4333, 1, '2021-12-30 06:10:01.749365', NULL, '2021-12-30 06:10:01.749365', '浦林成山(山东)轮胎有限公司', NULL);
INSERT INTO "public"."auditlog_log_line" VALUES (10, 1, 2, '中国人民财产保险股份有限公司威海市分公司', 4412, 1, '2021-12-30 06:10:01.749365', NULL, '2021-12-30 06:10:01.749365', '中国人民财产保险股份有限公司威海市分公司', NULL);
然后找到上一步根据特征行拆分的文件,他们的格式应该是类似于:
--
-- Data for Name: change_password_wizard; Type: TABLE DATA; Schema: public; Owner: odoo
--
COPY public.change_password_wizard (id, create_uid, write_uid, write_date, create_date) FROM stdin;
9 1 1 2021-06-03 01:32:19.293484 2021-06-03 01:32:19.293484
10 1 1 2021-06-18 03:10:30.937604 2021-06-18 03:10:30.937604
11 1 1 2021-11-10 07:26:22.03843 2021-11-10 07:26:22.03843
12 1 1 2022-04-21 08:43:53.089246 2022-04-21 08:43:53.089246
13 1 1 2022-04-21 08:44:56.657448 2022-04-21 08:44:56.657448
14 1 1 2022-04-21 08:46:36.041996 2022-04-21 08:46:36.041996
15 1 1 2022-04-21 08:47:47.267276 2022-04-21 08:47:47.267276
16 1 1 2022-04-21 08:49:35.377544 2022-04-21 08:49:35.377544
17 1 1 2022-04-21 08:53:36.79122 2022-04-21 08:53:36.79122
18 1 1 2023-02-27 07:34:04.423225 2023-02-27 07:34:04.423225
19 1 1 2023-05-31 02:50:56.048634 2023-05-31 02:49:41.244431把除了数据之外的东西全删了,变成这样:
9 1 1 2021-06-03 013219.293484 2021-06-03 013219.293484
10 1 1 2021-06-18 031030.937604 2021-06-18 031030.937604
11 1 1 2021-11-10 072622.03843 2021-11-10 072622.03843
12 1 1 2022-04-21 084353.089246 2022-04-21 084353.089246
13 1 1 2022-04-21 084456.657448 2022-04-21 084456.657448
14 1 1 2022-04-21 084636.041996 2022-04-21 084636.041996
15 1 1 2022-04-21 084747.267276 2022-04-21 084747.267276
16 1 1 2022-04-21 084935.377544 2022-04-21 084935.377544
17 1 1 2022-04-21 085336.79122 2022-04-21 085336.79122
18 1 1 2023-02-27 073404.423225 2023-02-27 073404.423225
19 1 1 2023-05-31 025056.048634 2023-05-31 024941.244431
20 1 1 2023-07-26 003505.650939 2023-07-26 003505.650939
21 1 1 2023-07-26 074721.418794 2023-07-26 074721.418794
22 1 1 2023-07-28 020920.553142 2023-07-28 020915.254526
23 1 1 2023-07-28 020926.714814 2023-07-28 020926.714814
24 1 1 2023-07-28 020932.358786 2023-07-28 020932.358786
25 1 1 2023-07-28 020938.048105 2023-07-28 020938.048105
26 1 1 2023-07-28 020943.347591 2023-07-28 020943.347591
27 1 1 2023-07-28 020947.737791 2023-07-28 020947.737791然后运行下面这个转换文件,转换为insert格式:java语言
注意修改文件路径.
package org.example;
import java.io.*;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Main {
public static void main(String[] args) {
String inputFilePath = "C:\\Users\\wpy\\Desktop\\123.txt"; // 输入文件路径
String outputFilePath = "C:\\Users\\wpy\\Desktop\\4.txt"; // 输出文件路径
try {
convertFileContent(inputFilePath, outputFilePath,"public","123");
System.out.println("File content converted successfully.");
} catch (IOException e) {
e.printStackTrace();
}
}
public static void convertFileContent(String inputFilePath, String outputFilePath, String schemaName, String tableName) throws IOException {
ExecutorService executor = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
try (BufferedReader reader = new BufferedReader(new FileReader(inputFilePath));
BufferedWriter writer = new BufferedWriter(new FileWriter(outputFilePath))) {
String line;
AtomicInteger count = new AtomicInteger();
while ((line = reader.readLine()) != null) {
final String currentLine = line;
executor.submit(() -> {
String[] parts = currentLine.split("\\s+");
int numParams = parts.length;
String regex = "\\d{4}-\\d{2}-\\d{2}";
Pattern pattern = Pattern.compile(regex);
if (numParams >= 2) {
StringBuilder values = new StringBuilder();
for (int i = 0; i < numParams; i++) {
// System.out.println(parts[i]);
if (i != 0) {
values.append(", ");
}
if (parts[i].equals("\\N")) {
values.append("null");
continue;
}
Matcher matcher = pattern.matcher(parts[i]);
if (matcher.matches()){
values.append("'").append(parts[i]+' '+parts[i+1]).append("'");
i++;
} else {
values.append("'").append(parts[i]).append("'");
}
}
String insertStatement = String.format(
"INSERT INTO \"%s\".\"%s\" VALUES (%s);",
schemaName, tableName, values.toString());
synchronized (writer) {
try {
writer.write(insertStatement);
writer.newLine();
count.getAndIncrement();
} catch (IOException e) {
e.printStackTrace();
}
}
}
});
}
executor.shutdown();
try {
executor.awaitTermination(Long.MAX_VALUE, TimeUnit.NANOSECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(count + " lines converted.");
}
}
}
然后在你指定的文件夹下得到了一个文件,结构类似于:
INSERT INTO "public"."123" VALUES ('17', '1', '1', '2022-04-21 085336.79122', '2022-04-21 085336.79122');
INSERT INTO "public"."123" VALUES ('16', '1', '1', '2022-04-21 084935.377544', '2022-04-21 084935.377544');
INSERT INTO "public"."123" VALUES ('23', '1', '1', '2023-07-28 020926.714814', '2023-07-28 020926.714814');
INSERT INTO "public"."123" VALUES ('15', '1', '1', '2022-04-21 084747.267276', '2022-04-21 084747.267276');
INSERT INTO "public"."123" VALUES ('10', '1', '1', '2021-06-18 031030.937604', '2021-06-18 031030.937604');
INSERT INTO "public"."123" VALUES ('24', '1', '1', '2023-07-28 020932.358786', '2023-07-28 020932.358786');
INSERT INTO "public"."123" VALUES ('20', '1', '1', '2023-07-26 003505.650939', '2023-07-26 003505.650939');
INSERT INTO "public"."123" VALUES ('22', '1', '1', '2023-07-28 020920.553142', '2023-07-28 020915.254526');
INSERT INTO "public"."123" VALUES ('11', '1', '1', '2021-11-10 072622.03843', '2021-11-10 072622.03843');
INSERT INTO "public"."123" VALUES ('19', '1', '1', '2023-05-31 025056.048634', '2023-05-31 024941.244431');
INSERT INTO "public"."123" VALUES ('18', '1', '1', '2023-02-27 073404.423225', '2023-02-27 073404.423225');
INSERT INTO "public"."123" VALUES ('12', '1', '1', '2022-04-21 084353.089246', '2022-04-21 084353.089246');
INSERT INTO "public"."123" VALUES ('9', '1', '1', '2021-06-03 013219.293484', '2021-06-03 013219.293484');
INSERT INTO "public"."123" VALUES ('14', '1', '1', '2022-04-21 084636.041996', '2022-04-21 084636.041996');
INSERT INTO "public"."123" VALUES ('21', '1', '1', '2023-07-26 074721.418794', '2023-07-26 074721.418794');
INSERT INTO "public"."123" VALUES ('13', '1', '1', '2022-04-21 084456.657448', '2022-04-21 084456.657448');
INSERT INTO "public"."123" VALUES ('26', '1', '1', '2023-07-28 020943.347591', '2023-07-28 020943.347591');
INSERT INTO "public"."123" VALUES ('25', '1', '1', '2023-07-28 020938.048105', '2023-07-28 020938.048105');
INSERT INTO "public"."123" VALUES ('27', '1', '1', '2023-07-28 020947.737791', '2023-07-28 020947.737791');2.2.3 合并文件
把刚才导出的sql文件的表头复制进入这个文件的开头,最终的结果类似于:
Source Schema : public
Target Server Type : PostgreSQL
Target Server Version : 110021
File Encoding : 65001
Date: 31/08/2023 22:20:03
*/
-- ----------------------------
-- Table structure for auditlog_log_line
-- ----------------------------
DROP TABLE IF EXISTS "public"."auditlog_log_line";
CREATE TABLE "public"."auditlog_log_line" (
"id" int4 NOT NULL DEFAULT nextval('auditlog_log_line_id_seq'::regclass),
"create_uid" int4,
"log_id" int4,
"new_value_text" text COLLATE "pg_catalog"."default",
"field_id" int4 NOT NULL,
"write_uid" int4,
"create_date" timestamp(6),
"old_value_text" text COLLATE "pg_catalog"."default",
"write_date" timestamp(6),
"new_value" text COLLATE "pg_catalog"."default",
"old_value" text COLLATE "pg_catalog"."default"
)
;
COMMENT ON COLUMN "public"."auditlog_log_line"."create_uid" IS 'Created by';
COMMENT ON COLUMN "public"."auditlog_log_line"."log_id" IS 'Log';
COMMENT ON COLUMN "public"."auditlog_log_line"."new_value_text" IS '更新后数据';
COMMENT ON COLUMN "public"."auditlog_log_line"."field_id" IS '字段名';
COMMENT ON COLUMN "public"."auditlog_log_line"."write_uid" IS 'Last Updated by';
COMMENT ON COLUMN "public"."auditlog_log_line"."create_date" IS 'Created on';
COMMENT ON COLUMN "public"."auditlog_log_line"."old_value_text" IS '旧数据';
COMMENT ON COLUMN "public"."auditlog_log_line"."write_date" IS 'Last Updated on';
COMMENT ON COLUMN "public"."auditlog_log_line"."new_value" IS '更新后数据';
COMMENT ON COLUMN "public"."auditlog_log_line"."old_value" IS '更新前数据';
COMMENT ON TABLE "public"."auditlog_log_line" IS 'Auditlog - Log details (fields updated)';
-- ----------------------------
-- Records of auditlog_log_line
-- ----------------------------
INSERT INTO "public"."123" VALUES ('17', '1', '1', '2022-04-21 085336.79122', '2022-04-21 085336.79122');
INSERT INTO "public"."123" VALUES ('16', '1', '1', '2022-04-21 084935.377544', '2022-04-21 084935.377544');
INSERT INTO "public"."123" VALUES ('23', '1', '1', '2023-07-28 020926.714814', '2023-07-28 020926.714814');
INSERT INTO "public"."123" VALUES ('15', '1', '1', '2022-04-21 084747.267276', '2022-04-21 084747.267276');
INSERT INTO "public"."123" VALUES ('10', '1', '1', '2021-06-18 031030.937604', '2021-06-18 031030.937604');
INSERT INTO "public"."123" VALUES ('24', '1', '1', '2023-07-28 020932.358786', '2023-07-28 020932.358786');
INSERT INTO "public"."123" VALUES ('20', '1', '1', '2023-07-26 003505.650939', '2023-07-26 003505.650939');
INSERT INTO "public"."123" VALUES ('22', '1', '1', '2023-07-28 020920.553142', '2023-07-28 020915.254526');
INSERT INTO "public"."123" VALUES ('11', '1', '1', '2021-11-10 072622.03843', '2021-11-10 072622.03843');
INSERT INTO "public"."123" VALUES ('19', '1', '1', '2023-05-31 025056.048634', '2023-05-31 024941.244431');
INSERT INTO "public"."123" VALUES ('18', '1', '1', '2023-02-27 073404.423225', '2023-02-27 073404.423225');
INSERT INTO "public"."123" VALUES ('12', '1', '1', '2022-04-21 084353.089246', '2022-04-21 084353.089246');
INSERT INTO "public"."123" VALUES ('9', '1', '1', '2021-06-03 013219.293484', '2021-06-03 013219.293484');
INSERT INTO "public"."123" VALUES ('14', '1', '1', '2022-04-21 084636.041996', '2022-04-21 084636.041996');
INSERT INTO "public"."123" VALUES ('21', '1', '1', '2023-07-26 074721.418794', '2023-07-26 074721.418794');
INSERT INTO "public"."123" VALUES ('13', '1', '1', '2022-04-21 084456.657448', '2022-04-21 084456.657448');
INSERT INTO "public"."123" VALUES ('26', '1', '1', '2023-07-28 020943.347591', '2023-07-28 020943.347591');
INSERT INTO "public"."123" VALUES ('25', '1', '1', '2023-07-28 020938.048105', '2023-07-28 020938.048105');
INSERT INTO "public"."123" VALUES ('27', '1', '1', '2023-07-28 020947.737791', '2023-07-28 020947.737791');然后去数据库里执行这个sql文件,就可以正确的在pgsql里面导入所需要的数据.
3.进行迁移:
使用安装时达梦数据库自带的DM数据迁移工具进行迁移。
在左上角新建.
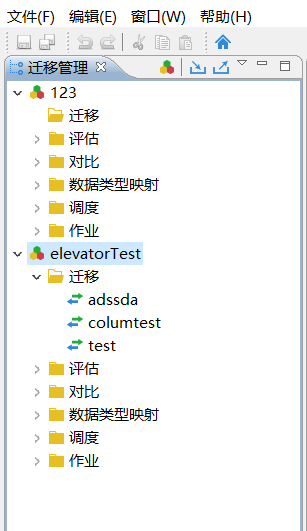
迁移方式选择从pgsql到达梦。
正确输入数据源pgsql相关连接信息。
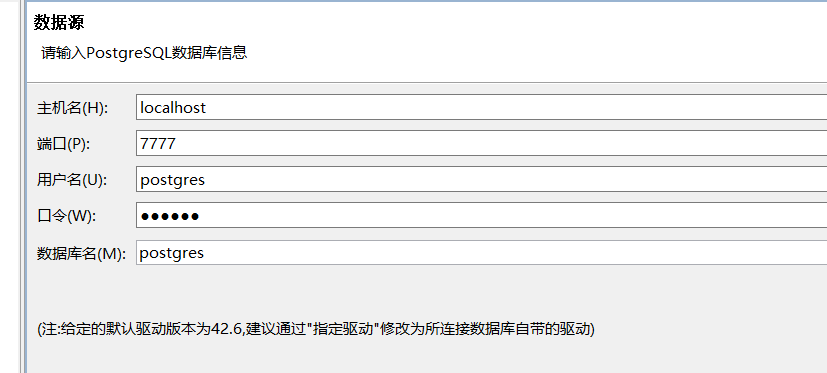
如果输入错误,则会报错导致无法进行下一步.
正确输入达梦数据库相关信息
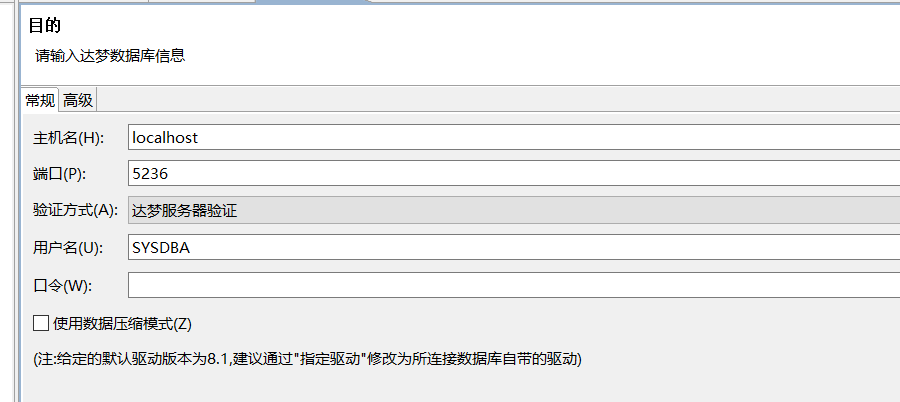
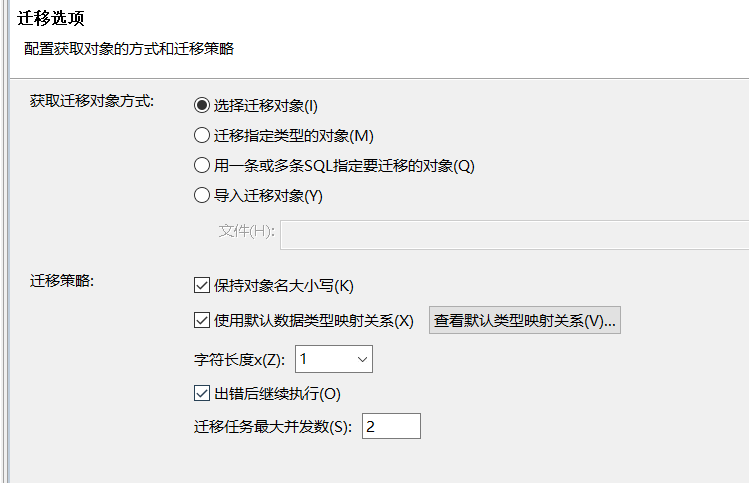
然后进入迁移选项,选择 “选择迁移对象”,迁移策略不用动,点击下一步。
进入指定模式,此处选择的是需要迁移的表。
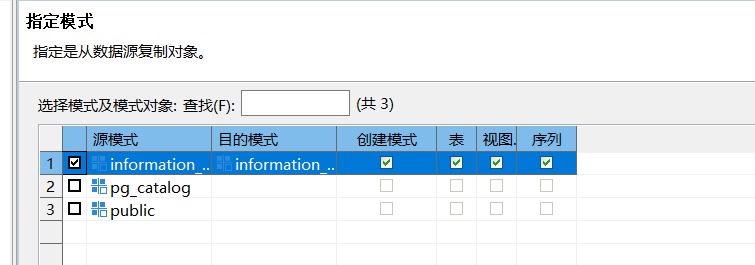
如果选择的表中什么都没有,下一步什么都不会出现,如果表中有内容,则会出现这样
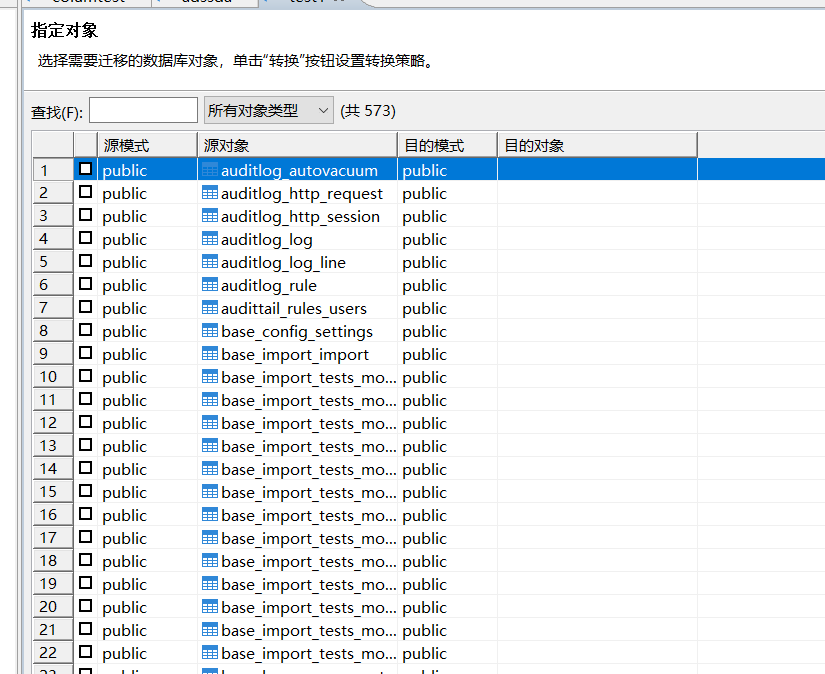
可以在这里修改模式.
选择要迁移的对象,然后就会出现目的模式和对象。
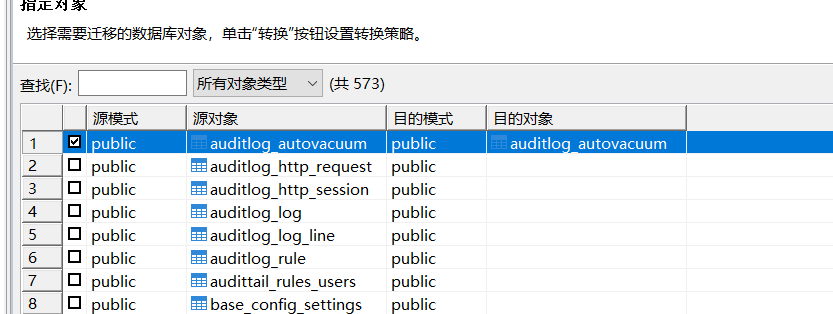
出现后,可以修改目的对象(即目的表中的表名).
如果是整张表迁移,可以直接点击下一步。
如果是按列进行迁移,则双击选中的这一行,点击出现设置表映射关系。
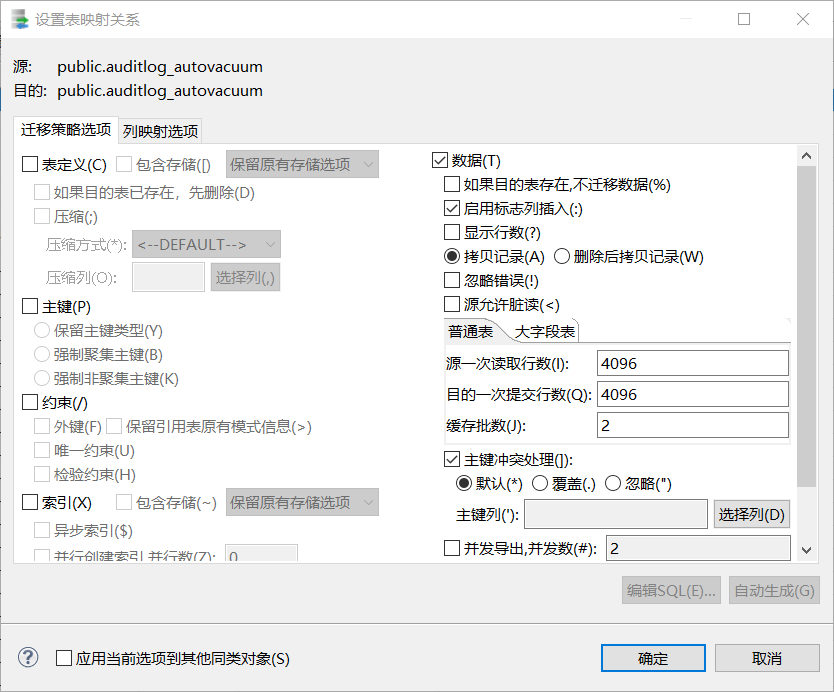
选择列映射选项.
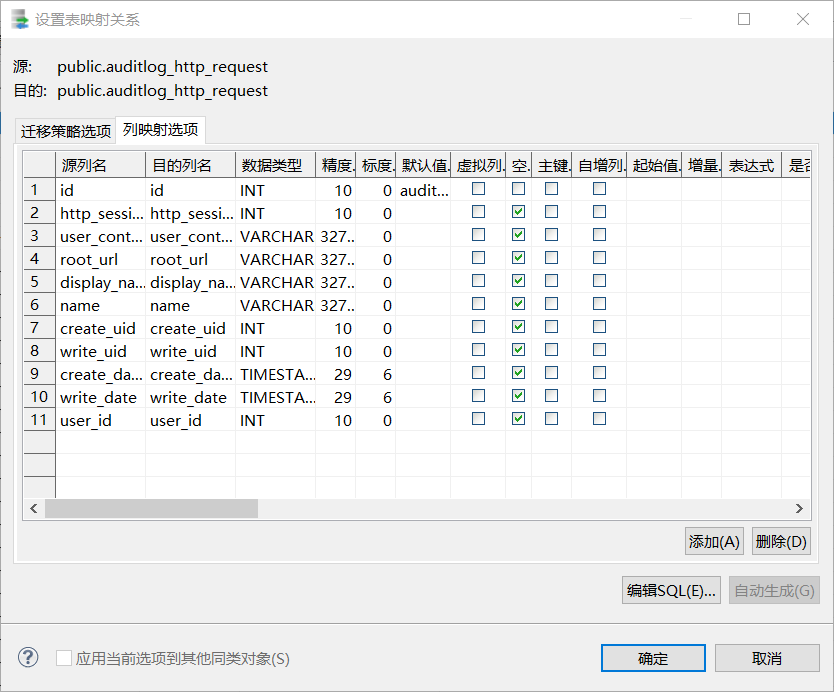
如果只需要迁移部分列,只需要把不需要迁移的部分列进行删除。
注意,这样要求你选择的表上必须有一个数据格式符合条件的字段,名字无所谓.如果没有则会报错.
完成之后,会弹出审阅迁移任务界面
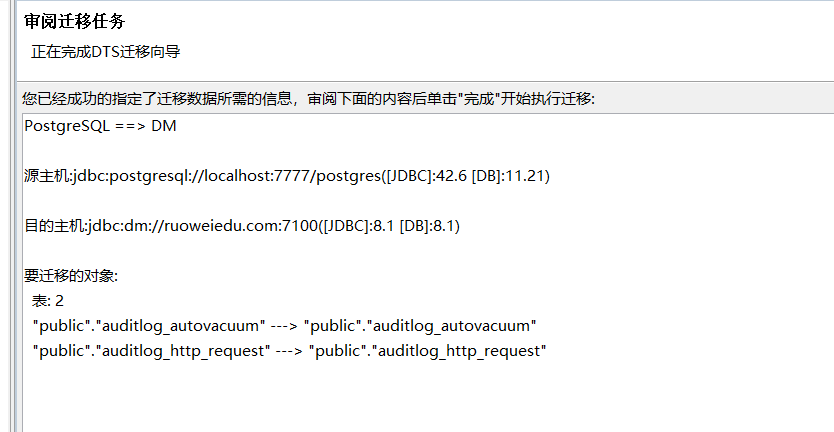
没有问题可以点击完成进行
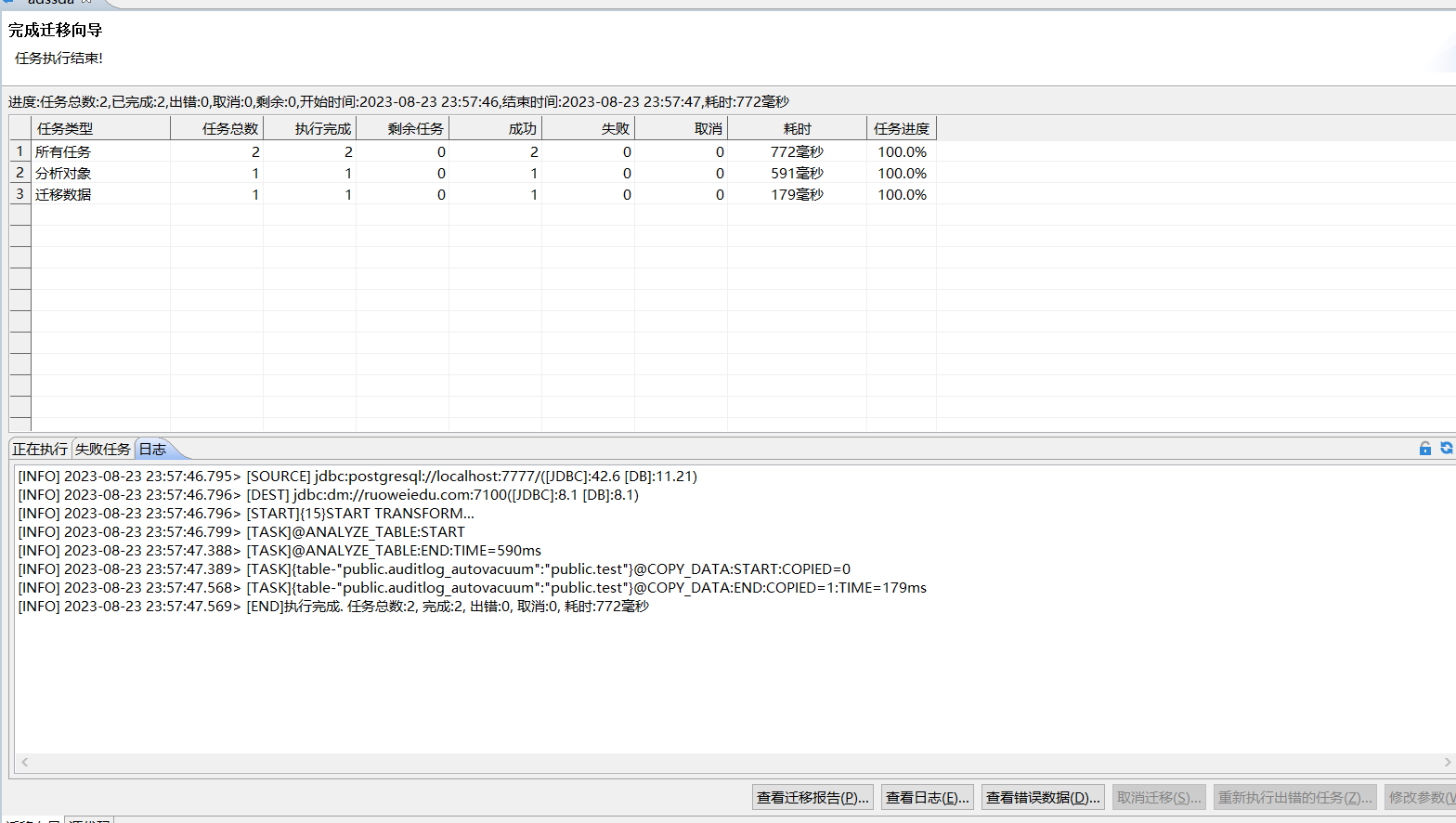
大批量按列迁移截图:
