Ulysses:应用容器化工具
本文最后更新于 2024-04-27,文章内容可能已经过时。
https://github.com/bearslyricattack/Ulysses.
仿照docker做的demo,还有很多不足的地方。
1.介绍
2.前置技术:
2.1 namespace:
2.1.1 介绍:
namespace 是 Linux 内核用来隔离内核资源的方式。通过 namespace 可以让一些进程只能看到与自己相关的一部分资源,而另外一些进程也只能看到与它们自己相关的资源,这两拨进程根本就感觉不到对方的存在。
以进程为例子,示意图如下:

2.1.2 类型:
linux提供七种隔离资源:

2.1.3 操作函数:
2.1.3.1 clone():
我们可以通过 clone() 在创建新进程的同时创建 namespace。
2.1.3.2 setns():
通过 setns() 函数可以将当前进程加入到已有的 namespace 中。
2.1.3.3 unshare():
通过 unshare 函数可以在原进程上进行 namespace 隔离。也就是创建并加入新的 namespace 。
2.1.4 go语言使用:
//调用init方法,/proc/self指的是自己运行的环境,init为传入的参数
cmd := exec.Command("/proc/self/exe", "init")
//创建新的进程
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS |
syscall.CLONE_NEWNET | syscall.CLONE_NEWIPC,
}2.2 cgroups:
2.2.1 介绍:
cgroups 的全称是control groups,cgroups为每种可以控制的资源定义了一个子系统。
cgroups 是Linux内核提供的一种可以限制单个进程或者多个进程所使用资源的机制,可以对 cpu,内存等资源实现精细化的控制.
2.2.2 组成:
主要由三部分组成:cgroup,subsystem,hierarchy.
一个cgroup包含一组进程。
一个subsystem制定了一组配置,可以和一个cgroup绑定起来.
cpu 子系统,主要限制进程的 cpu 使用率。
cpuacct 子系统,可以统计 cgroups 中的进程的 cpu 使用报告。
cpuset 子系统,可以为 cgroups 中的进程分配单独的 cpu 节点或者内存节点。
memory 子系统,可以限制进程的 memory 使用量。
blkio 子系统,可以限制进程的块设备 io。
devices 子系统,可以控制进程能够访问某些设备。
net_cls 子系统,可以标记 cgroups 中进程的网络数据包,然后可以使用 tc 模块(traffic control)对数据包进行控制。
freezer 子系统,可以挂起或者恢复 cgroups 中的进程。
ns 子系统,可以使不同 cgroups 下面的进程使用不同的 namespace。
hierarchy 的功能是把 cgroup串成一个树状的结构,一个这样的树便是hierarchy.
2.2.3 go语言使用:
//在系统默认创建挂载了 memory subsystem Hierarchy 上创建 cgroup
os.Mkdir(path.Join(cgroupMemoryHierarchyMount,”testmemorylimit”)'0755)
//将容器进程加入到这个 cgroup
ioutil.WriteFile(path.Join(cgroupMemoryHierarchyMount,”testmemorylimit”,
" tasks ”},[]byte(strconv.Itoa(cmd.Process.Pid)),0644)
//限制 cgroup 进程使用
ioutil WriteFile(path.Join(cgroupMemoryH erarchyMount,” testmemorylimit ”,
” memory.limit in bytes ”),[]byte(”lOOm”) ' 0644)2.3 Union File System:联合文件系统:
2004年由纽约州立大学开发,它可以把多个目录内容联合挂载到同一个目录下,而目录的物理位置是分开的。UnionFS可以把只读和可读写文件系统合并在一起,具有写时复制功能,允许只读文件系统的修改可以保存到可写文件系统当中。
它使用 branch把不同文件系统的文件和目录“透明地”覆盖,形成一个单一一致的文件系统 这些 branch或者是 read-only,或者是 read-write的,所以当对这个虚拟后的联合文件系统进行写操作的时候,系统是真正写到了一个新的文件中,看起来这个虚拟后的联合文件系统是可以对任何文件进行操作的,但是其实它并没有改变原来的文件.
2.3.1 挂载:
指的就是将设备文件中的顶级目录连接到 Linux 根目录下的某一目录(最好是空目录),访问此目录就等同于访问设备文件。
Linux 系统中“一切皆文件”,所有文件都放置在以根目录为树根的树形目录结构中。在 inux 看来,任何硬件设备也都是文件,它们各有自己的一套文件系统(文件目录结构)。
并不是根目录下任何一个目录都可以作为挂载点,由于挂载操作会使得原有目录中文件被隐藏,因此根目录以及系统原有目录都不要作为挂载点,会造成系统异常甚至崩溃,挂载点最好是新建的空目录。
可以把挂载理解为根目录文件映射。
2.3.2 写时复制(copy-on-write ):
如果一个资源是重复的,但没有任何修改,这时并不需要立即创建一个新的资源 这个资源可以被新旧实例共享。
创建新资源发生在第一次写操作,也就是对资源进行修改的时候.
通过这种资源共享的方式.可以显著地减少未修改资源复制带来的消耗.但是也会在进行资源修改时增加小部分的开销。
2.4 AUFS:Advanced Multi-Layered Unification Filesystem:
AUFS 完全重写了早期的UnionFS,其主要目的是为了可靠性和性能,井且引入了些新的功能,比如可写分支的负载均衡.Docker 就使用了AUFS.
2.4.1 实践:
2.4.1.1 准备文件:

2.4.1.2 修改挂载:

2.4.1.3 修改文件:

2.5 Linux proc 文件系统:
Linu 下的 proc 文件系统是由内核提供的,它其实不是一个真正的文件系统,只包含了系统运行时的信息( 比如系统内存、 mount设备信息、一些硬件配置等,它只存在于内存中,而不占用外存.它以文件系统的形式,为访问内核数据的操作提供接口。实际上,很多系统工具都是简单地去读取这个件系统的某个文件内容,比如 ls mod其实就是 cat proc modules.
当遍历这个目录的时候,会发现很多数字,这些都是为每个进程建的空间,数字就是它们的 PID.

3.构造容器:
3.1 构建cmd命令:
使用 github.com/urfave/cli 提供的命令行工具 的几个基本命令,实现基本命令的实现。
从main函数开始:
func main() {
app := cli.NewApp()
app.Name = "Ulysses"
app.Usage = usage
//命令行处理 共有两个命令
app.Commands = []cli.Command{
//启动容器
run.RunCommand,
//真正的启动方法
init.InitCommand,
}
app.Before = func(context *cli.Context) error {
// Log as JSON instead of the default ASCII formatter.
log.SetFormatter(&log.JSONFormatter{})
log.SetOutput(os.Stdout)
return nil
}
if err := app.Run(os.Args); err != nil {
log.Fatal(err)
}
}3.2 构建run命令:
3.2.1 命令行方法:
构建run命令的具体代码如下:
// RunCommand run方法执行逻辑,每个变量代表一个方法
var RunCommand = cli.Command{
Name: "run",
Usage: `Create a container with namespace and cgroups limit
mydocker run -ti [command]`,
//使用 --的形式指定参数
Flags: []cli.Flag{
cli.BoolFlag{
Name: "ti",
Usage: "enable tty",
},
},
//具体执行的方法
Action: func(context *cli.Context) error {
if len(context.Args()) < 1 {
return fmt.Errorf("missing container command")
}
var cmdArray []string
for _, arg := range context.Args() {
cmdArray = append(cmdArray, arg)
}
//获取传入的ti参数
tty := context.Bool("ti")
//处理参数,最终调用run方法
Run(tty, cmdArray, resConf)
return nil
},
}总的来说,这段代码注册了一个cmd方法,解析病获取参数,然后执行真正的run方法。
3.2.2 Run方法:
func Run(tty bool, comArray []string, res *subsystems.ResourceConfig) {
//首先调用NewParentProcess方法
parent, writePipe := NewParentProcess(tty)
if parent == nil {
log.Errorf("New parent process error")
return
}
if err := parent.Start(); err != nil {
log.Error(err)
}
parent.Wait()
}该方法主要就是调用NewParentProcess()方法.获取*exec.Cmd的parent对象。然后调用其start方法创建新的进程.
3.2.3 NewParentProcess方法:
func NewParentProcess(tty bool) (*exec.Cmd, *os.File) {
readPipe, writePipe, err := NewPipe()
if err != nil {
log.Errorf("New pipe error %v", err)
return nil, nil
}
//调用init方法,/proc/self指的是自己运行的环境,init为传入的参数
cmd := exec.Command("/proc/self/exe", "init")
//指定新进程的相关参数
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS |
syscall.CLONE_NEWNET | syscall.CLONE_NEWIPC,
}
if tty {
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
}
cmd.ExtraFiles = []*os.File{readPipe}
return cmd, writePipe
}exec.Command 方法不是直接创建新的进程,而是用于创建一个表示外部命令的 Cmd 结构体。这个结构体代表了一个可执行程序的执行上下文,包括了要执行的命令名称以及参数等信息。在调用 cmd.Run() 或者 cmd.Start() 方法后,会创建一个新的进程来执行这个命令。
当调用 cmd.Run() 方法时,会在当前的进程中启动一个新的子进程来执行指定的命令,等待该命令执行完成,并返回执行的结果。
通过设置 cmd.SysProcAttr 字段为一个 syscall.SysProcAttr 结构体,指定了一系列的 clone flags,用于创建一个具有特定命名空间的新进程。
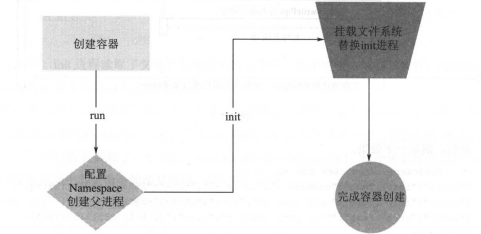
到现在,接下来执行的是init命令了。
3.3 构建init命令:
3.3.1 命令行方法:
var InitCommand = cli.Command{
Name: "init",
Usage: "Init container process run user's process in container. Do not call it outside",
Action: func(context *cli.Context) error {
log.Infof("init come on")
err := RunContainerInitProcess()
return err
},
}简单的调用RunContainerInitProcess方法.
3.3.2 RunContainerInitProcess方法:
func RunContainerInitProcess() error {
//setUpMount()
//使用 syscall.Exec 函数来替换当前进程的映像
if err := syscall.Exec(path, cmdArray[0:], os.Environ()); err != nil {
log.Errorf(err.Error())
}
return nil
}首先使用 mount 先去挂载 proc 文件系统.
然后使用syscall.Exec:实最终调用了Kernel int execve( const char lename char const argv[], cha r const envp []] ;这个系统函数。它的作用执行 filename 对应程序。它会覆盖当前进程的镜像、数据 堆械等信息,包括 PID 这些会被将要运行的进程覆盖掉。
通过这个方法,会将exec.Command 方法创建的新的进程给覆盖掉,这样当进入到容器内部的时候,就会发现容器内的第一个程序就是我们指定的进程了。
通过这两个命令,成功的启动了一个容器,流程图如下:

3.4 增加容器资源限制:
3.4.1 定义 Cgroups:
数据结构:
// ResourceConfig 内存,CPU限制
type ResourceConfig struct {
MemoryLimit string
CpuShare string
CpuSet string
}接口:
type Subsystem interface {
// Name 返回subsystem的名字
Name() string
// Set 设置cgroup中的限制
Set(path string, res *ResourceConfig) error
// Apply 添加进程
Apply(path string, pid int) error
// Remove 移除
Remove(path string) error
}3.4.2 编写接口实现:
以内存为例子:
type MemorySubSystem struct {
}
//返回subsystem的名字
func (s *MemorySubSystem) Name() string {
return "memory"
}
//设置 cgroupPath 对应的 cgroup 的内存资源限制
func (s *MemorySubSystem) Set(cgroupPath string, res *ResourceConfig) error {
//GetCgroupPath 的作用是获取当前 subsystem 在虚拟文件系统中的路径
if subsysCgroupPath, err := GetCgroupPath(s.Name(), cgroupPath, true); err == nil {
if res.MemoryLimit != "" {
//设置这个 cgroup 的内存限制,即将限制写入到 cgroup 对应目录的 memory.limit in bytes
文件中。
//本质上是对文件操作.
if err := ioutil.WriteFile(path.Join(subsysCgroupPath, "memory.limit_in_bytes"), []byte(res.MemoryLimit), 0644); err != nil {
return fmt.Errorf("set cgroup memory fail %v", err)
}
}
return nil
} else {
return err
}
}
// 删除 cgroupPath 对应的 cgroup
func (s *MemorySubSystem) Remove(cgroupPath string) error {
if subsysCgroupPath, err := GetCgroupPath(s.Name(), cgroupPath, false); err == nil {
return os.RemoveAll(subsysCgroupPath)
} else {
return err
}
}
//将一个迸程加入到 cgroupPath 对应的 cgroup
func (s *MemorySubSystem) Apply(cgroupPath string, pid int) error {
if subsysCgroupPath, err := GetCgroupPath(s.Name(), cgroupPath, false); err == nil {
// 写入对应的task文件.
if err := ioutil.WriteFile(path.Join(subsysCgroupPath, "tasks"), []byte(strconv.Itoa(pid)), 0644); err != nil {
return fmt.Errorf("set cgroup proc fail %v", err)
}
return nil
} else {
return fmt.Errorf("get cgroup %s error: %v", cgroupPath, err)
}
}
func (s *MemorySubSystem) Name() string {
return "memory"
}可见,上面对文件的读写操作都涉及到了GetCgroupPath函数.
3.4.3 GetCgroupPath函数:
//得到cgroup函数在文件系统中的绝对路径。
func GetCgroupPath(subsystem string, cgroupPath string, autoCreate bool) (string, error) {
cgroupRoot := FindCgroupMountpoint(subsystem)
if _, err := os.Stat(path.Join(cgroupRoot, cgroupPath)); err == nil || (autoCreate && os.IsNotExist(err)) {
if os.IsNotExist(err) {
if err := os.Mkdir(path.Join(cgroupRoot, cgroupPath), 0755); err == nil {
} else {
return "", fmt.Errorf("error create cgroup %v", err)
}
}
return path.Join(cgroupRoot, cgroupPath), nil
} else {
return "", fmt.Errorf("cgroup path error %v", err)
}
}这个函数又调用了FindCgroupMountpoint函数.
3.4.4 FindCgroupMountpoint函数:
func FindCgroupMountpoint(subsystem string) string {
f, err := os.Open("/proc/self/mountinfo")
if err != nil {
return ""
}
defer f.Close()
scanner := bufio.NewScanner(f)
for scanner.Scan() {
txt := scanner.Text()
fields := strings.Split(txt, " ")
for _, opt := range strings.Split(fields[len(fields)-1], ",") {
if opt == subsystem {
return fields[4]
}
}
}
if err := scanner.Err(); err != nil {
return ""
}
return ""
}打开了当前进程的挂载信息文件 /proc/self/mountinfo,它包含了当前进程的文件系统挂载信息。通过读取这个文件,可以获取当前进程的文件系统挂载情况,包括挂载的设备、挂载点、挂载选项等信息。
所以,这个函数的作用是得到 cgroup 在文件系统中的绝对路径.
3.4.5 mountinfo文件:
Linux系统的/proc/self/mountinfo记录当前系统所有挂载文件系统的信息:

这些行是来自 /proc/self/mountinfo 文件,它提供了有关当前进程的挂载信息。每一行表示一个文件系统的挂载点以及相关信息。
下面是每个字段的含义:
挂载 ID(Mount ID):挂载点的唯一标识符。
父挂载 ID(Parent Mount ID):父挂载点的唯一标识符。
设备编号(Major:Minor):文件系统的设备编号,通常是主设备号和次设备号的组合。
根挂载点(Root):文件系统的挂载点。
挂载点(Mount Point):文件系统被挂载到的目录。
挂载选项(Mount Options):文件系统的挂载选项,例如读写权限、是否允许 suid、设备节点是否可用等。
可选字段(Optional Fields):这部分包含了其他信息,例如文件系统类型、挂载标志等。
给出任意一行的解释:
第一行:
挂载 ID 为 24,父挂载 ID 为 18。
设备编号是 0:12,表示主设备号为 0(通常是指根文件系统)和次设备号为 12(可能是指挂载点
/sys/kernel/security对应的设备)。根挂载点是
/sys/kernel/security,挂载点是securityfs。挂载选项包括了
rw(读写)、nosuid(禁止 suid)、nodev(禁止设备文件)、noexec(禁止执行),以及relatime(相对访问时间更新)等。最后的可选字段为
-,表示没有指定额外信息。
Cgroup hierarchy 文件系统是通过 cgroup 类型文件系统 mount 挂载上去的,option 中加上 ub tem ,代表挂载 subsystem 类型 就可 mountinfo 中找到对应的subsystem的挂载目录了。
3.4.6 CgroupManager:
type CgroupManager struct {
// cgroup在hierarchy中的路径 相当于创建的cgroup目录相对于root cgroup目录的路径
Path string
// 资源配置
Resource *subsystems.ResourceConfig
}
func NewCgroupManager(path string) *CgroupManager {
return &CgroupManager{
Path: path,
}
}
// 将进程pid加入到这个cgroup中
func (c *CgroupManager) Apply(pid int) error {
for _, subSysIns := range subsystems.SubsystemsIns {
subSysIns.Apply(c.Path, pid)
}
return nil
}
// 设置cgroup资源限制
func (c *CgroupManager) Set(res *subsystems.ResourceConfig) error {
for _, subSysIns := range subsystems.SubsystemsIns {
subSysIns.Set(c.Path, res)
}
return nil
}
// 释放cgroup
func (c *CgroupManager) Destroy() error {
for _, subSysIns := range subsystems.SubsystemsIns {
if err := subSysIns.Remove(c.Path); err != nil {
logrus.Warnf("remove cgroup fail %v", err)
}
}
return nil
}通过 CgroupManager ,将资源限制的配置,以及将进程移动到 cgroup 中的操作交给各个subsystem 去处理。
3.4.7 整体流程:

CgroupManager 在配置容器资源限制时,首先会初始化 Subsystem 的实例,然后遍历调用 Subsystem 实例的 Set 方法,创建和配置不同 Subsystem 挂载的 hierarchy 中的cgroup ,最后再通过调用 Subsystem 实例将容器的进程分别加入到那些cgroup 中,实现容器的资源限制。
3.4.8 容器启动时限制:
增加了容器限制的run方法:
func Run(tty bool, comArray []string, res *subsystems.ResourceConfig) {
//首先调用NewParentProcess方法
parent, writePipe := NewParentProcess(tty)
if parent == nil {
log.Errorf("New parent process error")
return
}
if err := parent.Start(); err != nil {
log.Error(err)
}
///创建 cgroup manager ,并通过调用 set apply 设置资源限制并使限制在容器上生效
cgroupManager := cgroups.NewCgroupManager("mydocker-cgroup")
defer cgroupManager.Destroy()
//设置资源限制
cgroupManager.Set(res)
//应用
cgroupManager.Apply(parent.Process.Pid)
sendInitCommand(comArray, writePipe)
parent.Wait()
}3.5 管道:
当在 inux 上创建两个进程时,进程之间的通信一般就会使用管道的机制。
一般来说,管道都是半双工的,一端进行写操作,另外一端进行读操作。
管道是文件的一种 但是它和文件通信的区别在于 管道有一个固定大小的缓冲区,大小一般是4k 。当管道被写满 ,写进程就会被阻塞,直到有读进程把管道的内容读出来。同样 ,当读进程 管道 拿数据的时候,如果这时管道的内容是空的,那么读进程同样会被阻塞 一直等到有写进程向管道内写数据。
通过管道,实现父子进程之间的大量通信,传递大量参数。
3.5.1 管道的创建:
func NewPipe() (*os.File, *os.File, error) {
read, write, err := os.Pipe()
if err != nil {
return nil, nil, err
}
return read, write, nil
}3.5.2 管道的使用:
cmd.ExtraFiles = []*os.File{readPipe}3.6 总结:
对于 Cgroups 通过这一章在容器上增加可配置的选项,可以实现对于容器可用资源的控制.
最后,使用管道机制将用户输入的命令传递给容器初始化进程,实现了数据的传递.
4.构造镜像:
4.1 pivot_root:
是一个系统调用,修改当前的文件系统。
pivot root 可以将前进程的 root 文件系统移动到 put_old 文件夹中,然后使 new_root 成为新的 root 文件系统。
4.2 使用 AUFS包装:
在使用景象创建容器时,会新建两个layer:
write layer 是容器唯一的可读写层.
container-init layer 是为容器新建的只读层,用来存储容器启动时传入的系统信息.
然后把write layer,container iit layer 和相关镜像的layers挂载到mount的mnt 目录下,然后把这个 mnt 目录作为容器启动的根目录。
这样,在删除容器的时候在删除容器的时候, 容器对应 Write Layer,Container-init Layer会被删除,而保留镜像所有的内容。
流程图如下:

4.3 实现 volume 数据卷:
但是一旦容器退出,容器可写层的所有内容都会被删除。那么,如果用户需要持久化容器里的部分数据该
怎么办呢? volume 就是用来解决这个问题的。本节将会介绍如何实现将宿主机的目录作为数据卷挂载到容器中,
井且在容器退出后,数据卷中的内容仍然能够保存在宿主机上。
挂载数据卷的过程如下:
首先,读取宿主机文件目录 URL ,创建宿主机文件目录(/root/$ {parentUrl })。
然后,读取容器挂载点 URL,在容器文件系统里创建挂载点 C/root/rnnt/${containerUrl })
最后,把宿主机文件目录挂载到容器挂载点。这样启动容器的过程,对数据卷的处理也就完成了。
func MountVolume(rootURL string, mntURL string, volumeURLs [)string) {
//创建宿主机文件目录
parentUrl := volumeURLs[O]
if err:= os . Mkdir(parentUrl, 0777); err!= nil {
log. Infof (”Mkdir parent dir 毛 s error. ”, parentUrl err)
//在容器文件系统里创建挂载
containerUrl := volumeURLs[l)
containerVolumeURL : = mntURL + containerUrl
if err := os.Mkdir(conta nerVolumeURL, 0777); err != nil {
log.Infof (”Mkdir container dir error. ”, containerVolumeURL err)
//把宿主机文件目录挂载到容器挂载点
dirs :=”dirs=" + parentUrl
cmd := exec.Command (”mount”,”-t ”,”auf ”,”-。”, di rs, ” none”, containerVolumeURL)
cmd . Stdout = os .Stdout
cmd .Stderr = os.Stderr
if err := cmd.Run(); err != nil {
log . Errorf ("Mount volume failed ”, err)
}
}现在创建文件系统的过程如下:
1.创建只读层。
2.创建容器读写层。
3.创建挂载点井把只读层,读写层挂载到挂载点上。
4.判断 volume 是否为空,如果是,就表示用户并没有使用挂载标志,结束创建过程。
5.如果不为空 ,则使用 volumeUr!Extract 函数解析 volume 字符串。
6.volumeUr!Extract 函数返回的字符数组长度为 ,并且数据元素均不为空的时候,则执行 Mount folume 函数来挂载数据卷。
7.否则,提示用户新建数据卷输入值不对。
流程图如下:

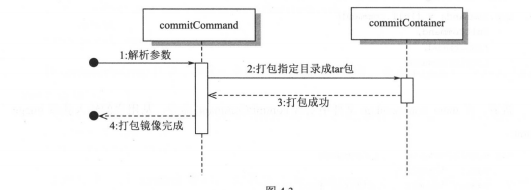
4.4 实现镜像打包:
通过调用linux系统自带的tar打包命令实现打包.
5.容器网络:
5.1 Linux 虚拟网络设备:
Linux 实际是通过网络设备去操作和使用网卡的,系统装了一个网卡之后会为其生成一个网络设备实例,比如 eth0。
随着网络虚拟化技术的发展, Linux 支持创建出虚拟化的设备,可以通过虚拟化设备的组合实现多种多样的功能和网络拓扑,常见的虚拟化设备:
Vet
Bridge
802.1.q VLAN device
TAP
5.2 Veth:
Veth 是成对出现的虚拟网络设备.发送 Veth一端虚拟设备的请求会从另一端的虚拟设备中发出。
在容器的虚拟化场景中,经常会使用Veth连接不同的网络Namespace.
示意图如下:
[/]$#创建两个网络 Names pace
[/]$ sudo ip netns add nsl
[ /] $ sudo ip netns add ns2
[/]$#创建 Veth
[/]$ sudo ip l 工 nk add vethO type veth peer name vethl
[/]$#分别将两个 Veth 移到两个 Name space
[/]$ sudo ip link set vethO netns nsl
[/]$ sudo ip link set vethl netns ns2
[/]$#去 nsl names pace 中查看网络设备
[/]$ sudo ip netns exec nsl ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1
link/loopback 00:00:00:00:00 : 00 brd 00:00 : 00 : 00 : 00 : 00
17: veth0@if16: <BROADCAST , MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT
group default qlen 1000
link/ether Be:bb:18:8a:c2 : 85 brd ff:ff:ff : ff : ff : ff link- netnsid 1在ns1和2的命名空间中,就只看到了veth另一个网络设备。
当给两端分配不同的地址后,从虚拟网络设备的一端发送请求,另一端就能收到。

5.3 Linux Bridge:
Brid 虚拟设备是用来桥接的网络设备,它相当于现实世界中的交换机。
可以连接不同的网络设备,当请求到达 Bridge 设备时,可以通过报文中的 Ma 地址进行广播或转发。

5.4 Lim 路由表:
路由表是 Linux 内核的 个模块,通过定义路由表来决定在某个网络namespace中包的流向,从而定义请求会到哪个网络设备上。
[/]$#启动虚拟网络设备,并设置它在 Net Namespace 中的 IP 地址
[ /]$ sudo ip link set vethO up
[/]丰 sudo ip link set brO up
[ /] $ sudo ip netns exec nsl ifconfig vethl 172 .1 8 . 0. 2/24 up
[/]$#分别设置 nsl 网络空间的路由和宿主机上的路由
(/] $ #default 代表 0.0/0 即在 Net Namespace 中所有流量都经过 vethl 网络设备流出
[/]$ sudo ip netns exec nsl route add d e f ault dev vethl
[/]$#在宿主 上将 172.18.0.0/24 的网段请求路由 brO 网桥
[/]$ sudo route add -net 172 . 18 . 0 . 0/24 dev brO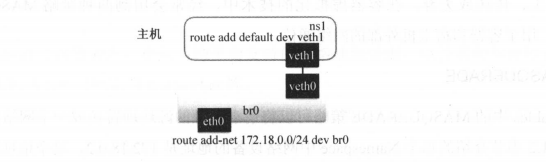
通过设置路由,对IP地址的请求就能正确的被路由到相应的网络设备上,从而实现通信。
5.5 Linux iptables:
iptables 是对 Linux 内核的 netfilter 模块进行操作和展示的工具,用来管理包的流动和转送。
iptables 定义了一套链式处理的结构,在网络包传输的各个阶段可以使用不同的策略对包进行加工、传送或丢弃。
在容器虚拟化的技术中,经常会用到两种策略 MASQUERADE和DNAT ,用于容器和宿主机外部的网络通信。
5.5.1 MASQUERADE:
iptables 中的 MASQUERADE 策略可以将请求包中的源地址转换成一个网络设备的地址。
在Namespace 中请求宿主机外部地址时,将 Namespace 中的源地址转换成宿主机的地址作为源地址,就可以在 Namespace 中访问宿主机外的网络了。
5.5.2 DNAT:
iptables 中的 DNAT 策略也是做网络地址的转换,不过它是要更换目标地址,经常用于将内部网络地址的端口映射到外部去。
[/]$#将到宿主机上 80 端口的请求转发到 Namespace IP
[/] $ sudo iptables -t nat -A PREROUTING -p tcp -m tcp --dport 80 -j DNAT --to•destination 172.18.0.2 : 80这样就可以把宿主机上 80 端口的 TCP 请求转发到 Namespace 中的地址 172.18.0.2:80 ,从而实现外部的应用调用。
5.6 Go 语言网络库:
5.6.1 net:
net 库是 Go 语言内置的库,提供了跨平台支持的网络地址处理,以及各种常见协议的 IO支持,比如 TC UDP, DNS Unix Socket 等。
5.6.2 github.com/vishvananda/netlink:
github .com/vishvananda/netl ink Go 语言的操作网络接口、路由表等配置的库 ,使用它的调用相当于我们通过 IP 命令去管理网络接口。
5.6.3 github com/vishvananda/netns:
是 Go 言版进出 Net Namespace 库,通过这个库,可以让 netlink库中配置网络接口的代码在某个容器的 Net amespace 中执行。
5.7 构建容器网络模型:
5.7.1 整体模型:
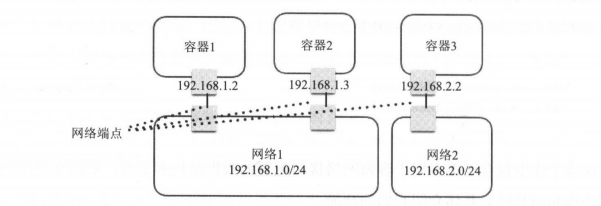
容器网络的两个对象一一网络和网络端点。
5.7.2 网络:
网络是容器的一个集合,在这个网络上的容器可以通过这个网络互相通信,就像挂载到同一个Linux Bridge设备上的网络设备一样,可以直接通过Bridge设备实现网络互连;连接到同一个网络中的容器也可以通过这个网络和网络中别的容器互连。网络中会包括这个网络相关的配置,比如网络的容器地址段、网络操作所调用的网络驱动等信息。
5.7.3 网络端点:
网络端点是用于连接容器与网络的,保证容器内部与网络的通信。像上一节中用到的Veth设备,一端挂载到容器内部,另一端挂载到Bridge上,就能保证容器和网络的通信。网络端点中会包括连接到网络的一些信息,比如地址、Veth设备、端口映射、连接的容器和网络等信息。
而网络端点的信息传输需要靠网络功能的两个组件配合完成,这两个组件分别为网络驱动和IPAM,具体介绍如下。
5.7.4 网络驱动:
网络驱动(Network Driver)是一个网络功能中的组件,不同的驱动对网络的创建、连接、销毁的策略不同,通过在创建网络时指定不同的网络驱动来定义使用哪个驱动做网络的配置。
5.7.5 IPAM:
IPAM也是网络功能中的一个组件,用于网络IP地址的分配和释放,包括容器的IP地址和网络网关的IP地址。
5.7.6 创建网络:

5.8 容器地址分配:
5.8.1 bitmap算法:
bitmap算法,也叫位图算法,在大规模连续且少状态的数据处理中有很高的效率,比如要用到的IP地址分配。
在网段中,某个IP地址有两种状态,1表示已经被分配了,0表示还未被分配,那么一个IP地址的状态就可以用一位来表示,并且通过这一位相对基础位的偏移也能够迅速定位到数据所在的位。
例如,图6.8中的内存IP地址位的列表,通过地址相对于192.168.0.0/24的偏移找到所在的位,然后通过位中的值是0还是1去管理地址分配的信息。

